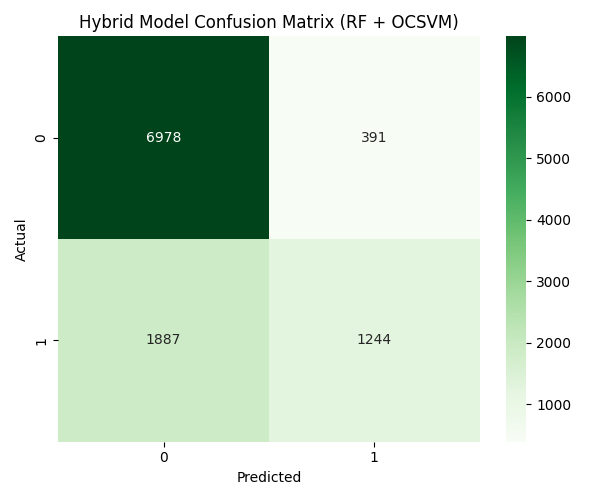
Understanding the data
before modeling.
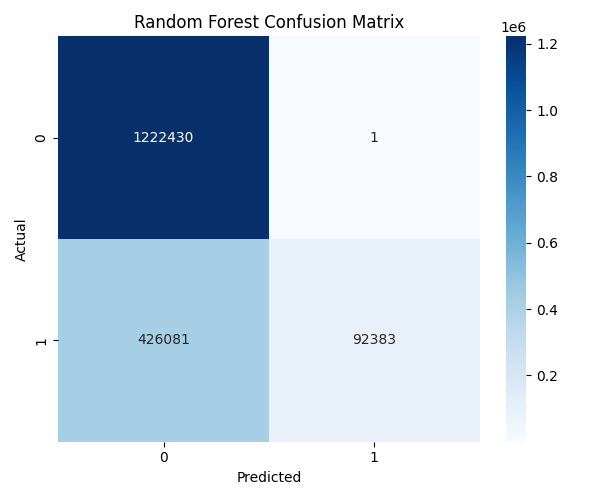
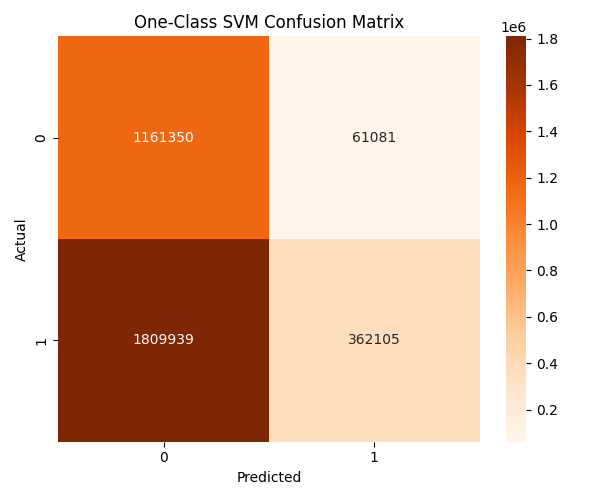
8.2 million network flows — 74% benign, 26% attacks across 14 categories. Raw data contains infinite values, high correlations, and identifier columns that leak topology.
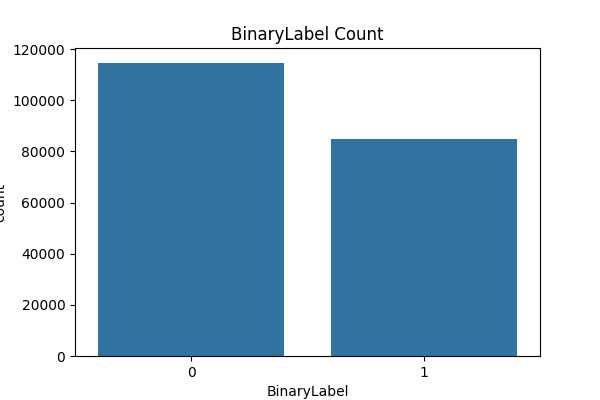
Binary Label Distribution — Benign vs Attack
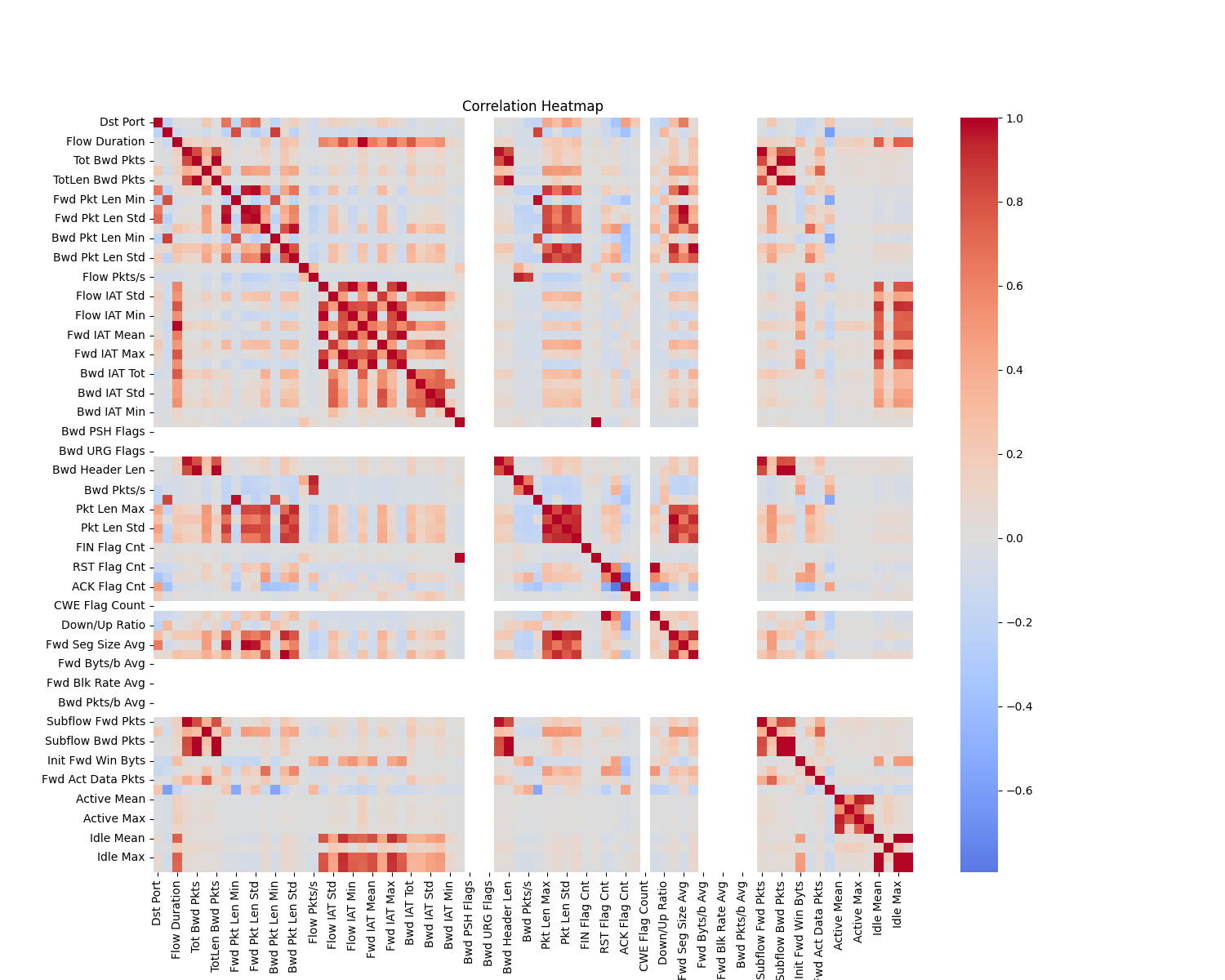
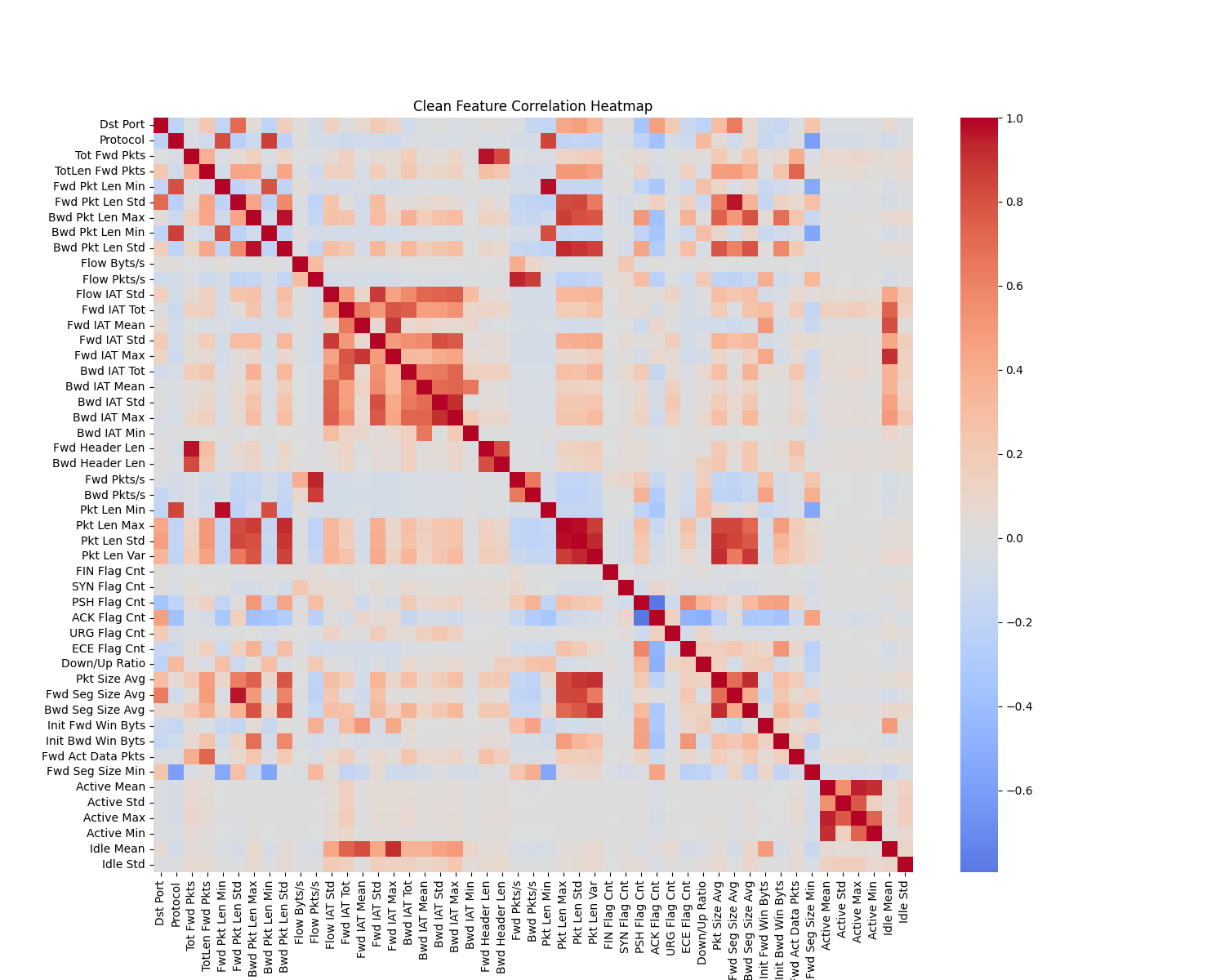
Correlation Heatmap — Dense redundancy blocks

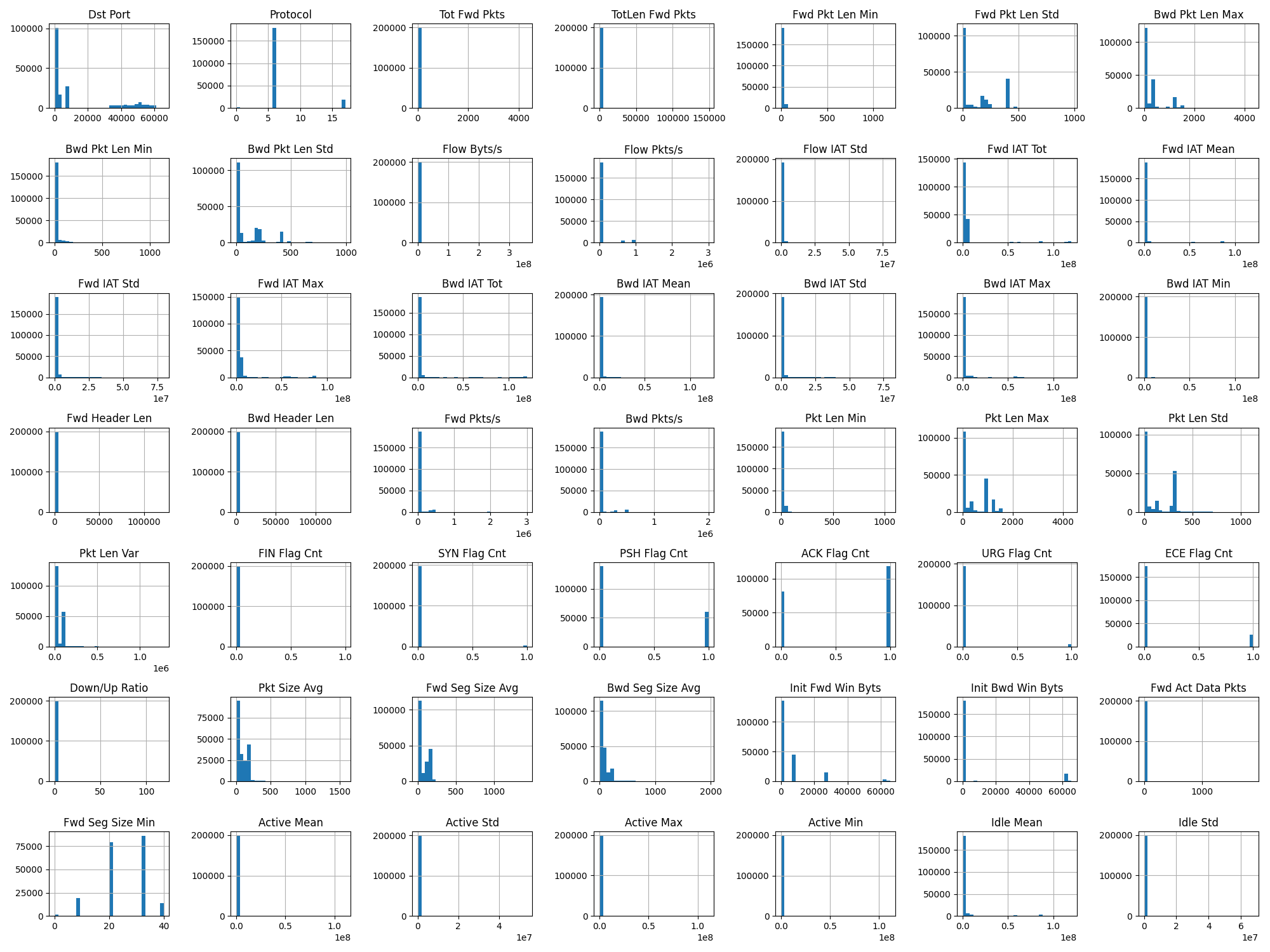
Feature Histograms — Heavy-tailed, skewed, full of outliers
Preprocessing Steps
1. Dropped identifiers (Flow ID, IPs, Timestamp) →
2. Replaced
inf/-inf with NaN →
3. Dropped columns with >50% missing values →
4. Filled remaining NaN with 0 →
5. Normalized labels to lowercase